1 Introducción
Una breve historia
Bosquejar el desarrollo del campo de estudio hoy conocido como Machine Learning o aprendizaje automático puede abordarse desde, al menos, dos puntos de vista: el estadístico y el computacional.
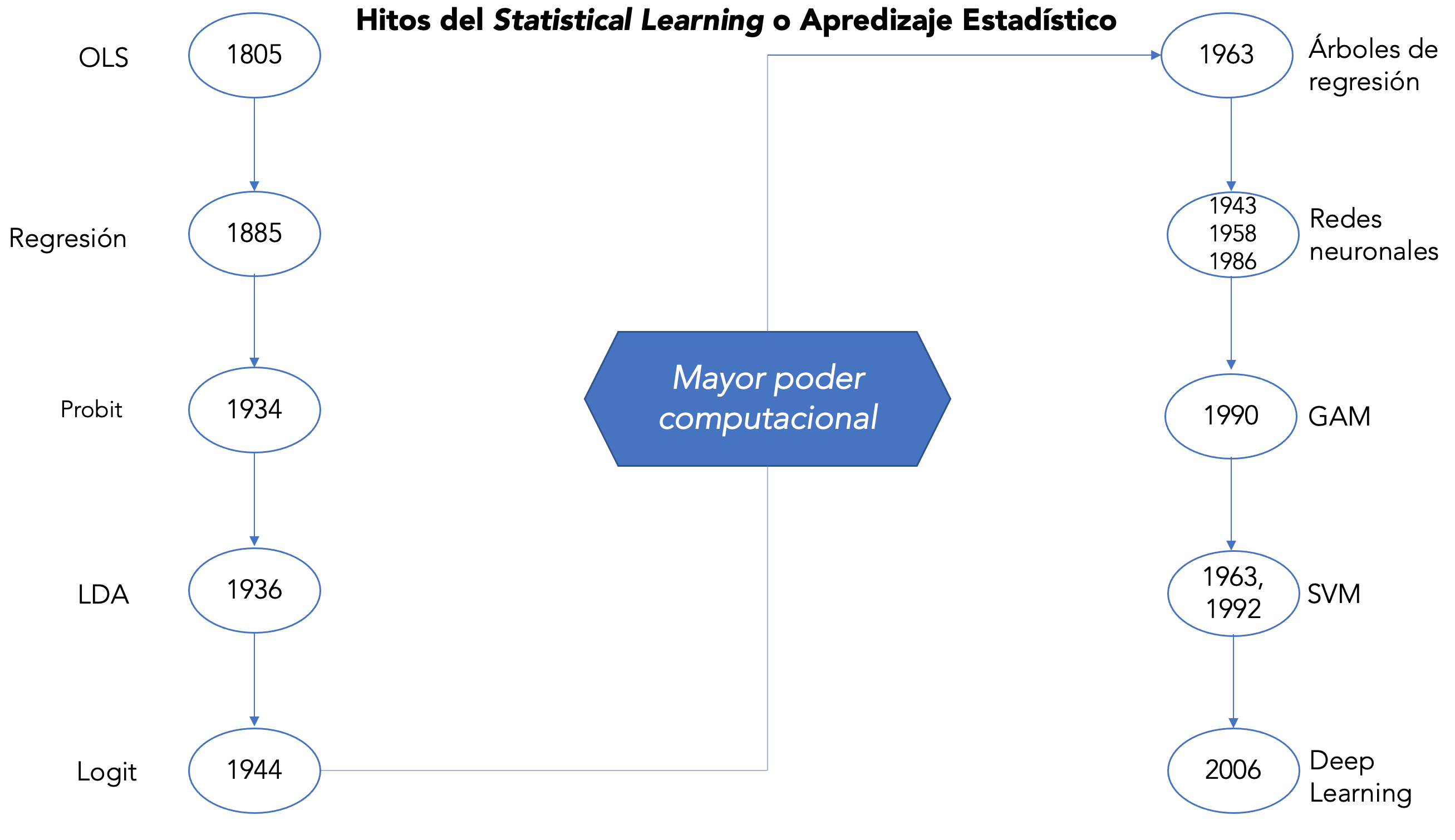
Desde el punto de vista estadístico, el método de mínimos cuadrados presentado por Legendre en 1805 (Legendre (1806)) 1, junto con la regresión lineal -desarrollado por Francis Galton en 1885 (Galton (1889))- fue inicialmente aplicado en problemas de astronomía. Hoy se usa la regresión para explicar y predecir variables cuantitativas como salario, ingreso, altura, entre otras. Luego, para tratar variables cualitativas como empleado o no empleado, bueno o malo, entre otros, Sir. Ronald Fisher propone en 1936 el método de análisis discriminante lineal (Fisher (1936)).
Otros métodos para variables cualitativas aparecen en los años 40 (probit (Bliss (1934)) y logit (Berkson (1944)) siendo los más populares) consolidándose en la aparición del método de modelos lineales generalizados em 1972 (Nelder and Wedderburn (1972)) de los que los modelos probit y logit son casos especiales.
Sin embargo, como se puede apreciar, casi todos los métodos se orientaban a un enfoque lineal porque las relaciones no lineales implicaban mayor poder computacional que se alcanza en los años 80. Con este nuevo desarrollo computacional aparecen métodos como árboles de regresión (Morgan and Sonquist (1963)), modelos aditivos generalizados (Nelder and Wedderburn (1972)), redes neuronales (Rosenblatt (1961)) y máquinas de soporte vectorial (Vapnik and Chervonenkis (1964)). Todas estas nuevas técnicas desarrolladas tanto en lo teórico como en lo práctico son ahora conocidas como statistical learning (aprendizaje estadístico), un campo del Machine Learning o Aprendizaje Automático, que a su vez es un sub campo de la Inteligencia Artificial (AI). Pero, como no se puede ser inteligente sin aprender, el Machine Learning es central en el desarrollo de la inteligencia artificial.
La siguiente imagen resume brevemente los hitos sobre los que se han desarrollado los métodos de aprendizaje estadístico.
1.1 Machine Learning (ML)
Una máquina aprende cuando es capaz de acumular experiencia (a través de datos, programas, etc.) y desarrollar nuevos conocimientos para que su desempeño en tareas específicas mejore con el tiempo. (Izenman (2008))
El ML supone un cambio de paradigma, tanto desde un punto de vista estadístico como computacional. En lo computacional, la siguiente imagen presenta cambio (adatpado de Chollet and Allaire (2018)):
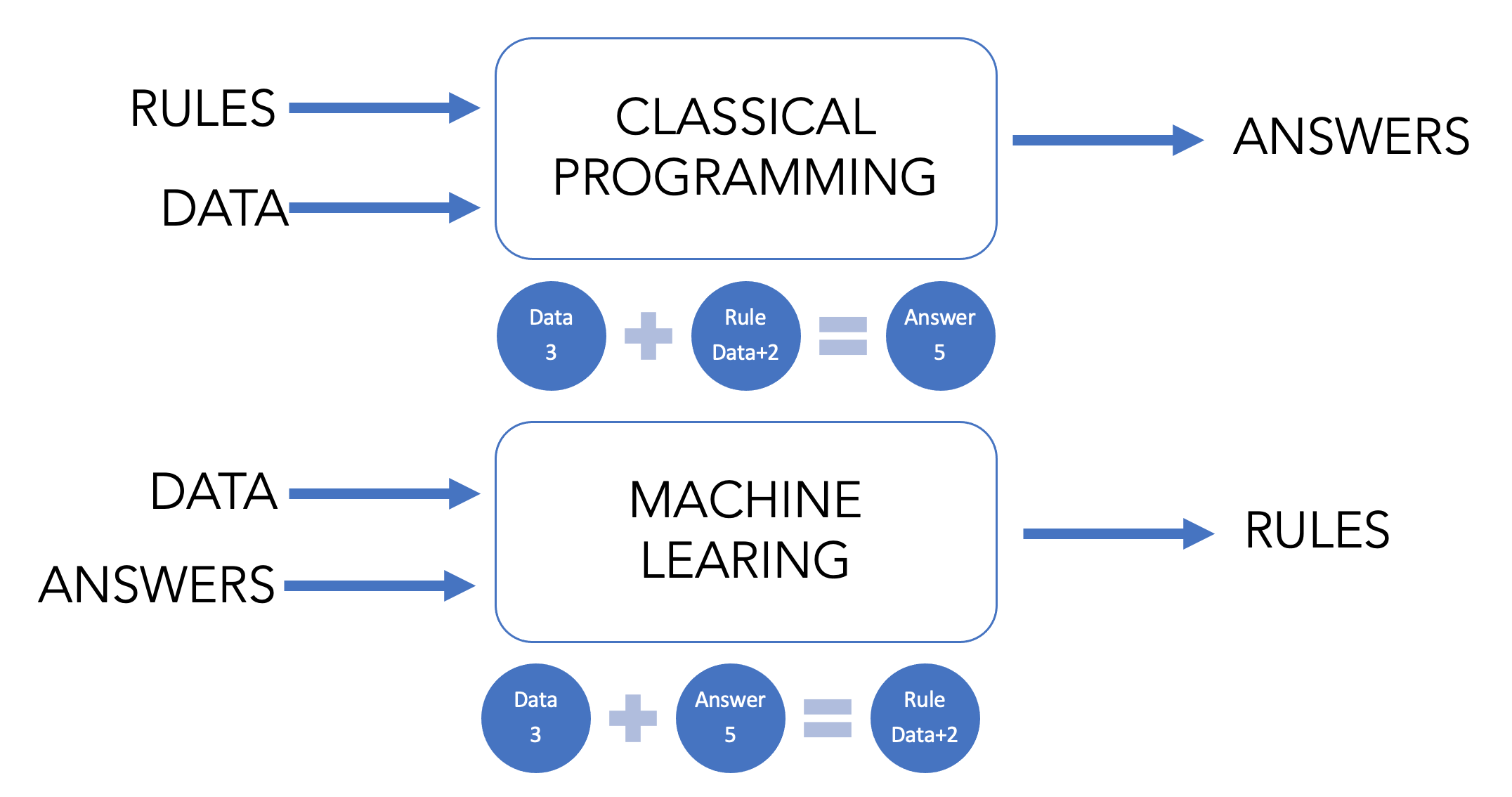
En los inicios de la AI, se pensaba que era suficiente que se tenga un ejército de programadores que listen una conjunto gigante de reglas que sean aplicadas a datos y así obtener respuestas, este enfoque se conoce como AI simbólica. Hoy se lo considera como programación clásica donde se tiene un conjunto de reglas & datos que dan como resultado respuestas. Sin embargo, al enfrentarse a problemas más complejos como clasificación de imágenes, reconocimiento de voz y traducción de idiomas este paradigma se queda corto.
La nueva propuesta que trae el ML es una donde se tiene datos & respuestas para obtener reglas. Estas reglas pueden ser usadas en nuevos conjuntos de datos para generar respuestas.
1.1.1 Clasificación del ML
En el aprendizaje supervisado (SML), el algoritmo de aprendizaje recibe un conjunto de datos de entrada (continuos o discretos) y una variable de respuesta correcta, con esta información trata de encontrar una función de los datos de entrada para aproximar la variable de respuesta. SML se compone de clasificación, donde el resultado es categórico, y regresión, donde el resultado es numérico. Otro nombre con el que se refiere a este punto en la literatura es data mining predictivo.
En el aprendizaje no supervisado (UML), no se proporciona una variable de respuesta, y el algoritmo de aprendizaje se centra en la detección de estructuras, relaciones, tendencias, conglomerados y/o atípicos en los datos de entrada. Otro nombre con el que se refiere a este punto en la literatura es data mining descriptivo.
1.1.2 Usos y pasos para aplicar ML
El ML has sido usado en:
- Predecir los resultados de las elecciones.
- Identificar y filtrar los mensajes no deseados del correo electrónico.
- Prever actividad criminal.
- Automatice las señales de tráfico según las condiciones de la carretera.
- Producir estimaciones financieras de tormentas y desastres naturales.
- Examinar la rotación de clientes.
- Crear aviones de pilotaje automático y automóviles de conducción automática.
- Identificar individuos con la capacidad de donar.
- Dirigir publicidad a tipos específicos de consumidores.
Para aplicar ML se necesitan tres elementos clave:
Datos
Variable de respuesta
Una manera de medir si el algoritmo está haciendo un buen trabajo.
Pasos para aplicar ML
Recopilación de datos: si los datos están escritos en papel, grabados en archivos de texto y hojas de cálculo, almacenados en una base de datos SQL o en cualquier sistema de información, deberás reunirlos en un formato electrónico adecuado para el análisis. Esta información servirá como el material que usa un algoritmo para aprender.
Explorar y preparar los datos: la calidad de cualquier proyecto de aprendizaje automáticose basa en gran medida en la calidad de los datos que utiliza. Este paso en el proceso de ML tiende a requerir una gran cantidad de intervención humana. Un estadística citada a menudo sugiere que el 80 por ciento del esfuerzo en el aprendizaje automático está dedicado a preparar datos. Gran parte de este tiempo se dedica a aprender más sobre los datos y sus matices durante una práctica llamada exploración de datos (EDA o data mining descriptivo).
Este paso incluye lo que se conoce como represetación o codificación de datos (data encoding). Por ejemplo, una imagen de color puede codificarse en formato RGB (red, green, blue) o formato HSV (Hue, Saturation, Value – Matiz, Saturación, Valor) que son dos codificaciones diferentes de los mismos datos. Otras codificaciones incluyen tipos de estandarización o cambio de coordenadas. Una codificación puede ser más útil que otra según el problema al que nos enfrentamos.
Seleccionar y entrenar un modelo: cuando los datos han sido preparados para el análisis, es probable que tengas una idea de lo que esperas aprender de los datos. La tarea específica de aprendizaje automático informará la selección de un algoritmo apropiado, y el algoritmo representará los datos en la forma de un modelo.
Evaluación del rendimiento del modelo: porque cada modelo de aprendizaje automático resulta en una solución sesgada al problema de aprendizaje, es importante evaluar qué tan bien el algoritmo aprendió de su experiencia. Dependiendo del tipo de modelo utilizado, es posible que puedas evaluar la precisión del modelo que usas en un conjunto de datos de prueba, o puedes necesitar desarrollar medidas de rendimiento específico para la aplicación prevista.
Mejora del rendimiento del modelo: si se necesita un mejor rendimiento, es necesario utilizar estrategias más avanzadas para aumentar el rendimiento del modelo. A veces, puede ser necesario cambiar a un tipo diferente de modelo. Es posible que necesites complementar tus datos con más recopilación de datos, o realizar trabajos preparatorios adicionales como en el paso dos de este proceso.





























